AI Workload Intelligence: Track AI Usage Patterns
Most organizations can name their approved AI providers.
Far fewer can answer which workloads are actually communicating with them.
Which workloads are driving the majority of AI activity?
Which AI providers appeared in your environment this week?
Sentrilite automatically inventories, attributes, classifies, and trends AI workload activity across your infrastructure — in real time.
No SDK. No application code changes. No API credentials. 2 minutes to install. Start tracking AI workload activity immediately.


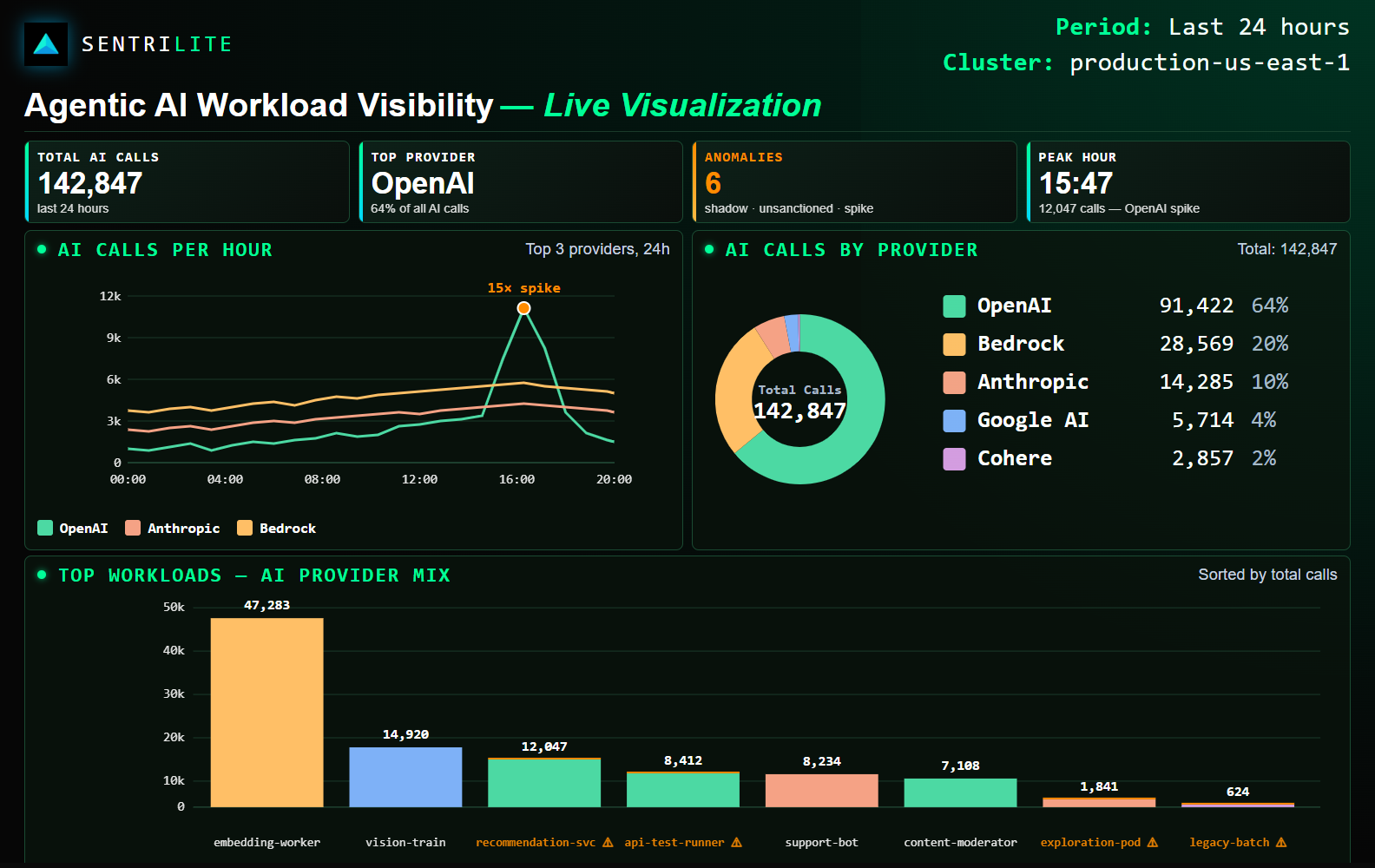
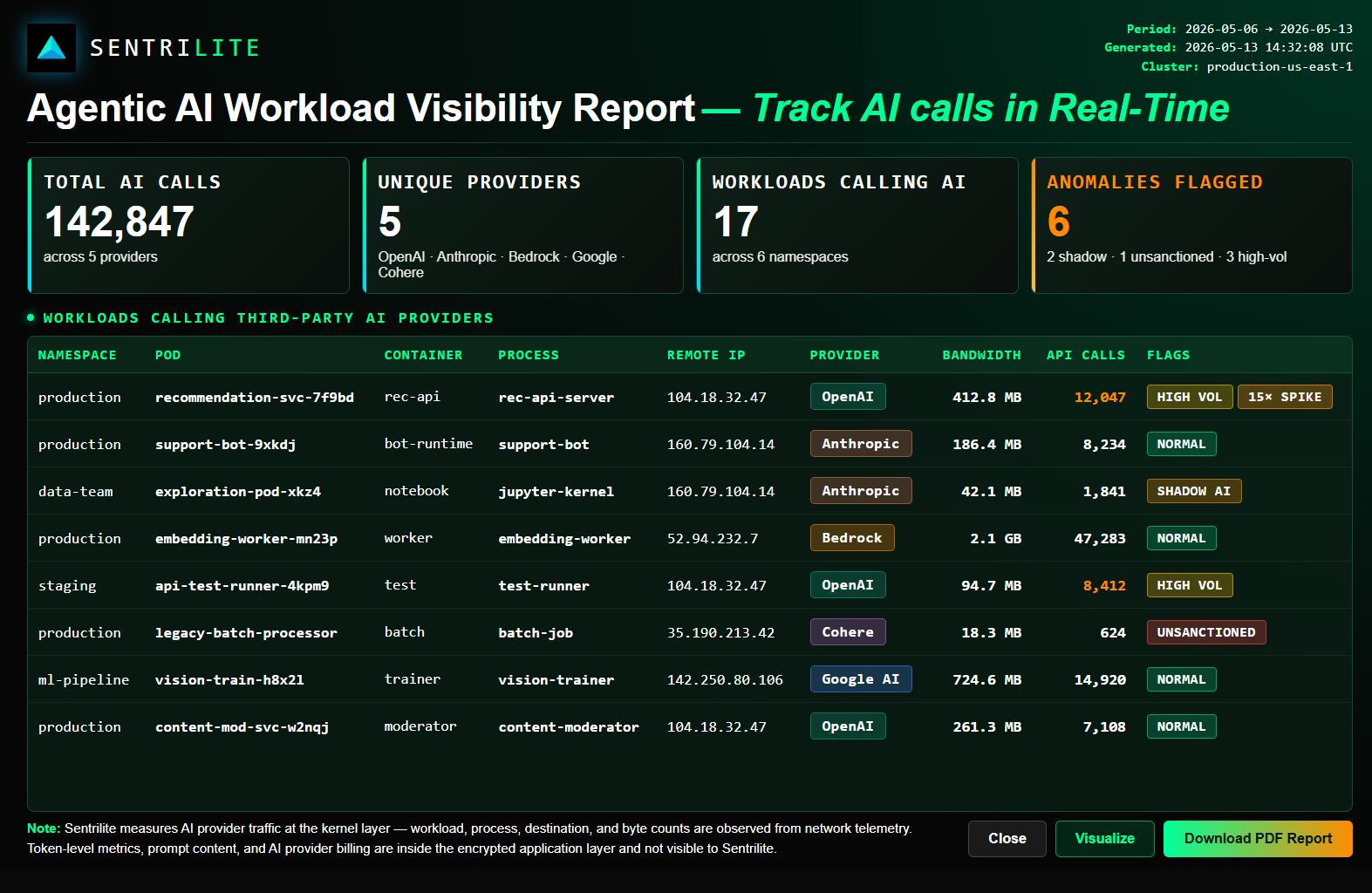
Sentrilite provides real-time AI Workload Intelligence for Kubernetes and cloud environments. By observing runtime network activity, Sentrilite automatically inventories, attributes, classifies, and trends AI provider usage across workloads — helping organizations understand how AI is being adopted throughout their infrastructure.
- Discover which workloads are communicating with OpenAI, Anthropic, AWS Bedrock, Google Gemini, Cohere, and other AI providers
- Identify the workloads driving the majority of AI activity and track adoption trends over time
- Detect newly observed AI providers and verify they align with approved governance policies
- Surface Shadow AI activity from workloads, services, and environments that were never intended to use external AI services
- Track AI workload growth and usage patterns across teams, namespaces, and environments
- Automatically generate AI Workload Insights, including provider adoption, workload concentration, ownership, and trend analysis
- Understand which workloads are responsible for AI activity spikes and investigate unusual changes before they become governance, security, or cost concerns
No code changes. No SDKs. No proxies. Deploy in minutes.
What Sentrilite Surfaces
Workload-level network behavior for every AI call in your environment — visible without instrumentation, without API keys, without changing a single line of application code.
Workload → AI Provider Mapping
See exactly which Kubernetes pod, container, or process is calling OpenAI, Anthropic, AWS Bedrock, Google Gemini, Cohere, Mistral, and others. Attribution down to the process and destination level.
Usage Pattern Classification
Every (workload, provider) pair is classified in real time — context-heavy, instruction-heavy, generation-heavy, or balanced — so platform and FinOps teams know what kind of work each AI integration is actually doing. See the four categories below.
Bytes Sent & Received Per Workload
Separate ingress and egress counters per workload per AI provider. Build a baseline of normal AI usage and detect when the shape of consumption changes over time.
AI Workload Insights
Automatic observations: which workloads dominate AI traffic, which providers are new this period, which workloads spiked, which patterns shifted. Surfaced as ready-to-review headlines for governance reviews.
Shadow AI Detection
Surface AI calls happening in your environment that nobody knew about. Workloads bypassing your AI gateway, unauthorized API keys, dev environments hitting production AI providers, or third-party libraries calling AI behind the scenes.
Real-Time Alerts
Alert when a new workload starts calling AI providers. Alert when call volume exceeds a threshold. Alert when AI calls cross regions or use unsanctioned credentials.
No Instrumentation, Ever
Works at the kernel level via eBPF. No SDK to install. No proxy to route through. No code changes. The agent runs as a single DaemonSet and sees every outbound connection in your cluster.
Usage Pattern Categories
Not every workload uses an AI provider the same way. Sentrilite classifies every workload's AI activity into one of four patterns, in real time — so the right operational and governance conversations happen in the right places.
● Context-Heavy Workloads
Large context windows, document analysis, and retrieval-based workflows. These workloads push substantial amounts of data to AI providers — a key signal for governance teams reviewing what data is in scope.
● Instruction-Heavy Workloads
Classification, extraction, scoring, and structured task execution. These workloads send detailed prompts and receive compact answers — typically high volume, lower per-call cost.
● Generation-Heavy Workloads
Content creation, code generation, and long-form responses. These workloads produce substantial output — the category that disproportionately drives output-token spend across providers.
● Balanced Workloads
Conversational assistants and interactive AI applications. Roughly symmetric traffic in both directions — typical of chat, Q&A, and multi-turn dialogue workloads.
Classification is based on workload-level network behavior, not application-layer inspection. Sentrilite does not see prompts, responses, or token counts. The goal isn't content inspection — it's helping platform, engineering, and governance teams understand how AI is being consumed.
Use Cases
Real observations Sentrilite surfaces from kernel-level network attribution. Each scenario below is the kind of finding you'd see in a typical AI Workload Insights report.
Platform and FinOps teams rarely have a clear picture of which workloads dominate AI usage. Sentrilite computes concentration automatically, so optimization, capacity, and budget conversations focus on the handful of services that matter most.
AI adoption spreads organically across teams. Sentrilite surfaces every new workload calling an AI provider for the first time — so governance, security, and FinOps teams can verify approval status before usage scales.
New providers enter environments quietly — a developer experiment, a third-party library, a forked service. Sentrilite identifies the first observed call to any AI provider not previously seen, so it can be reviewed against the approved-provider list.
Sudden growth in a workload's AI usage can be a feature launch, a runaway loop, or a credential issue. Sentrilite catches period-over-period spikes automatically, with the workload identity and provider attribution attached, so the right team can investigate immediately.
Total usage of an AI provider can grow rapidly when new workloads adopt it. Sentrilite identifies the provider-level shift and traces it back to the workload responsible — useful for FinOps planning, capacity reviews, and policy enforcement.
Why Shadow AI Matters
Most enterprises have zero visibility into where AI calls originate in their fleet. Developers experiment, prototypes ship to production, AI usage spreads through teams — and the security, compliance, and FinOps teams find out months later.
Shadow AI is the next shadow IT problem
Three years ago, the question was "which SaaS tools are our engineers using without IT knowing?" Today, the question is "which AI providers are our workloads calling without anyone tracking it?"
SDK-based AI observability tools (Helicone, Langfuse, LangSmith, OpenLLMetry) only see what's instrumented to go through them. They miss:
- Developers calling OpenAI directly with a personal API key
- Forked services that don't use the company's AI gateway
- Internal scripts and cron jobs making AI calls outside any monitoring
- Production workloads still on legacy AI integrations from before the gateway existed
- Third-party libraries that quietly call AI providers behind the scenes
Sentrilite sees all of it because it watches the network, not the SDK. Every outbound TCP connection from every workload, regardless of how the application was written.
What Sentrilite Does Not Do
Sentrilite does not provide real-time token usage of AI API calls. We surface workload-level network activity — which workloads are calling which AI providers, at what frequency and byte volume. Token-level metrics live inside the encrypted application layer.